Leaving Wordpress for Static
Last month I migrated this site from wordpress to eleventy and moved from siteground to github.io.
The first challenge was porting content out of wordpress. For this site that didn’t entail much, but another I ported to aws had several hundred posts. After a limited search for utilities to assist, I decided to use the vanilla wordpress export to xml and then tweak my own migration script in Python. Python’s ElementTree for the xml and BeautifulSoup for building markdown were indispensible.
With ElementTree I extracted the posts from the export. The tricky part was referencing the xml namespaces to pull certain attributes. Once all the posts’ content and metadata were assembled, I passed the data to BeautifulSoup to navigate the HTML tags embedded in the content and translate it to markdown.
root_node = ET.parse('kentskyoexport.xml').getroot()
for i, post in enumerate(root_node.findall('channel/item')):
post_type = post.find('{http://wordpress.org/export/1.2/}post_type').text
if post_type != "post":
continue
title = post.find('title').text
link = post.find('link').text
# xml namespaced references
post_date = post.find('{http://wordpress.org/export/1.2/}post_date').text
post_name = post.find('{http://wordpress.org/export/1.2/}post_name').text
content = post.find(
'{http://purl.org/rss/1.0/modules/content/}encoded').text
tags = ["post"]
categories = []
for t in post.findall('category'):
d = t.get('domain')
if d == 'post_tag':
tags.append(html.unescape(t.text))
elif d == 'category':
categories.append(html.unescape(t.text))
writemd(title, categories, tags, post_date,
content, post_name)One very useful feature in BeautifulSoup allowed me to strip out the voluminous html comments wrapping content which the new guttenberg editor injected to facilitate its block operations…
from bs4 import BeautifulSoup, Comment
s = BeautifulSoup(content, 'html.parser')
# strip comments
for comment in s.findAll(text=lambda text: isinstance(text, Comment)):
comment.extract()After that it was just a matter of translating HTML tags and their content to markdown with a series of replacements and unwraps.
for tag in s('img'):
src = tag['src']
alt = tag.get('alt', '')
img = image_loader(src)
tag.replace_with(
"\n\n".format(alt, img["fn"]))
for tag in s('blockquote'):
bq = ""
if tag.string:
bq = tag.string
else:
for child in tag.children:
if child.string:
bq += child.string + "\n "
tag.replace_with("> "+bq)
for tag in s('h1'):
tag.insert(0, "# ")
tag.unwrap()
etc...A markdown file was created with frontmatter for each post. Explicit encoding was required…
fm = frontMatter(title, categories, tags, post_date, index)
fs = html.unescape(markdown(content))
f = open('./src/posts/{0}.md'.format(post_name), 'w',
encoding='utf-8')
print(fm + '\n'+'## '+title+'\n\n'+fs, file=f)
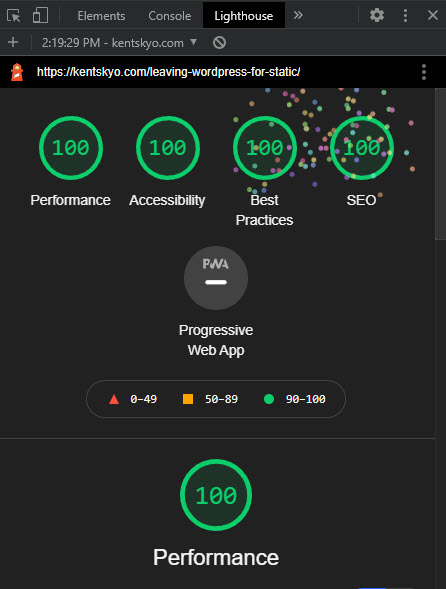
f.close()Future posts may cover other aspects of the migration and life in a static world. It is a refreshing change to be able to play again with just vanilla html and css and craft bespoke pages and components without frameworks or pre-fab templates. And the lighthouse reports are encouraging as well: